Interval Keyakinan
Apa itu Interval Keyakinan:
Ini adalah perkiraan rentang yang digunakan dalam statistik, yang berisi parameter populasi. Parameter populasi yang tidak diketahui ini ditemukan melalui model sampel yang dihitung dari data yang dikumpulkan .
Contoh: rata-rata sampel yang dikumpulkan x̅ mungkin atau tidak cocok dengan rata-rata populasi sebenarnya μ. Untuk ini, dimungkinkan untuk mempertimbangkan berbagai sarana sampel di mana rata-rata populasi ini dapat terkandung. Semakin lama interval ini, semakin besar kemungkinan ini terjadi.
Interval kepercayaan dinyatakan sebagai persentase, didenominasi oleh tingkat kepercayaan, dengan 90%, 95% dan 99% yang paling ditunjukkan. Pada gambar di bawah, misalnya, kami memiliki interval kepercayaan 90% antara batas atas dan bawahnya (a dan -a ).
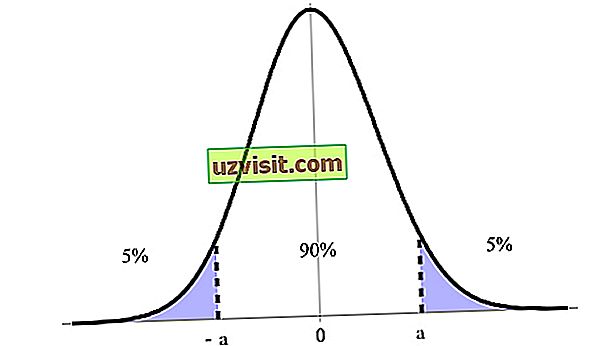
Interval Keyakinan adalah salah satu konsep terpenting dalam pengujian hipotesis dalam statistik, karena digunakan sebagai ukuran ketidakpastian. Istilah ini diperkenalkan oleh ahli matematika dan ahli statistik Polandia Jerzy Neyman pada tahun 1937.
Apa relevansi Interval Keyakinan?
Interval kepercayaan penting untuk menunjukkan margin ketidakpastian (atau ketidaktepatan) terhadap perhitungan yang dibuat. Perhitungan ini menggunakan sampel penelitian untuk memperkirakan ukuran aktual hasil dalam populasi sumber.
Perhitungan interval kepercayaan adalah strategi yang mempertimbangkan pengambilan sampel kesalahan. Ukuran hasil penelitian Anda dan interval kepercayaan Anda menjadi ciri nilai yang diperkirakan untuk populasi asli.
Semakin sempit interval kepercayaan, semakin besar probabilitas bahwa persentase populasi penelitian mewakili jumlah nyata dari populasi sumber, memberikan kepastian yang lebih besar mengenai hasil objek penelitian.
Bagaimana cara mengartikan Interval Keyakinan?
Interpretasi yang benar dari interval kepercayaan mungkin merupakan aspek yang paling menantang dari konsep statistik ini. Contoh interpretasi konsep yang paling umum adalah sebagai berikut:
Ada kemungkinan 95% bahwa, di masa depan, nilai sebenarnya dari parameter populasi (misalnya rata-rata) berada dalam kisaran X (batas bawah) dan Y (batas atas).
Dengan demikian, interval kepercayaan ditafsirkan sebagai berikut: 95% yakin bahwa interval antara X (batas bawah) dan Y (batas atas) berisi nilai sebenarnya dari parameter populasi.
Akan benar - benar salah untuk menyatakan bahwa: ada kemungkinan 95% bahwa interval antara X (batas bawah) dan Y (batas atas) berisi nilai riil dari parameter populasi.
Pernyataan di atas adalah kesalahpahaman paling umum tentang interval kepercayaan. Setelah rentang statistik dihitung, ini hanya dapat berisi parameter populasi atau tidak.
Namun, interval dapat bervariasi di antara sampel, sedangkan parameter populasi sebenarnya adalah sama terlepas dari sampel.
Oleh karena itu, pernyataan keyakinan interval kepercayaan hanya dapat dibuat dalam kasus di mana interval kepercayaan dihitung ulang untuk jumlah sampel.
Langkah-langkah menghitung Interval Keyakinan
Kisaran dihitung menggunakan langkah-langkah berikut:
- Kumpulkan data sampel: n ;
- Hitung rata-rata sampel x̅;
- Tentukan apakah standar deviasi populasi ( σ ) diketahui atau tidak diketahui;
- Jika standar deviasi populasi diketahui, titik- z dapat digunakan untuk tingkat kepercayaan yang sesuai;
- Jika standar deviasi populasi tidak diketahui, kita dapat menggunakan statistik t untuk tingkat kepercayaan yang sesuai;
- Dengan demikian, batas bawah dan atas interval kepercayaan ditemukan menggunakan rumus berikut:
a) Standar deviasi populasi yang diketahui :
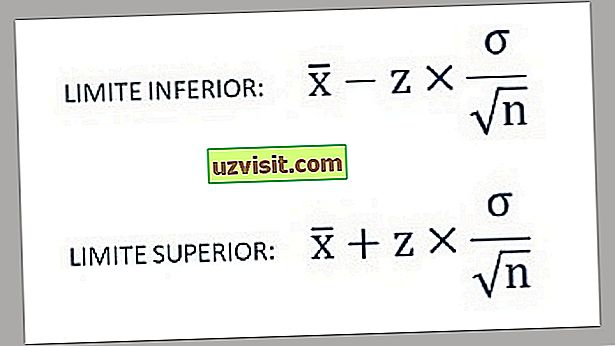
Formula untuk perhitungan standar deviasi dari populasi yang diketahui.
b) Deviasi standar populasi yang tidak dikenal :

Formula untuk perhitungan standar deviasi populasi yang tidak diketahui.
Contoh praktis dari interval kepercayaan
Sebuah studi klinis mengevaluasi hubungan antara keberadaan asma dan risiko mengembangkan Obstructive Sleep Apnea pada orang dewasa.
Beberapa orang dewasa direkrut secara acak dari daftar pejabat negara untuk diikuti selama empat tahun.
Peserta dengan asma, jika dibandingkan dengan mereka yang tidak, memiliki risiko lebih besar terkena apnea dalam empat tahun.
Dalam melakukan penelitian klinis seperti contoh ini, sebagian dari populasi yang diminati biasanya direkrut untuk meningkatkan efisiensi studi (lebih sedikit biaya dan lebih sedikit waktu).
Subkelompok individu ini, populasi yang diteliti, terdiri dari mereka yang memenuhi kriteria inklusi dan setuju untuk berpartisipasi dalam penelitian ini, seperti yang ditunjukkan pada gambar di bawah ini.

Kemudian, penelitian selesai dan ukuran efek (misalnya, perbedaan rata-rata atau risiko relatif ) dihitung untuk menjawab pertanyaan penelitian.
Proses ini, yang disebut inferensi, melibatkan penggunaan data yang dikumpulkan dari populasi penelitian untuk memperkirakan ukuran efek aktual pada populasi yang diminati, yaitu populasi asal.
Dalam contoh yang diberikan, para peneliti merekrut sampel acak pegawai negeri (populasi sumber) yang memenuhi syarat dan setuju untuk berpartisipasi dalam penelitian (populasi penelitian) dan melaporkan bahwa asma meningkatkan risiko pengembangan apnea pada populasi penelitian.
Untuk memperhitungkan kesalahan pengambilan sampel karena perekrutan hanya subkelompok dari populasi yang diminati, mereka juga menghitung interval kepercayaan 95% (sekitar perkiraan) dari 1, 06 - 1, 82, menunjukkan probabilitas 95 % bahwa risiko relatif sebenarnya dalam populasi sumber adalah antara 1, 06 dan 1, 82 .
Interval Keyakinan untuk Rata-Rata
Ketika seseorang memiliki informasi standar deviasi suatu populasi, seseorang dapat menghitung interval kepercayaan untuk rata-rata atau rata-rata populasi tersebut.
Ketika karakteristik statistik yang diukur (seperti pendapatan, IQ, harga, tinggi, jumlah atau berat) adalah numerik, dalam banyak kasus diperkirakan bahwa nilai rata-rata untuk populasi ditemukan.
Dengan demikian, kami mencoba untuk menemukan mean populasi ( μ ) menggunakan mean sampel ( x̅ ), dengan margin of error. Hasil perhitungan ini disebut interval kepercayaan untuk rata-rata populasi .
Ketika standar deviasi populasi diketahui, rumus untuk interval kepercayaan (CI) untuk rata-rata populasi adalah:

Dimana:
- x̅ adalah mean sampel;
- σ adalah simpangan baku populasi;
- n adalah ukuran sampel;
- Ζ * mewakili nilai yang sesuai dari distribusi normal standar untuk tingkat kepercayaan yang Anda inginkan.
Berikut ini adalah nilai untuk berbagai tingkat kepercayaan ( Ζ * ):
| Tingkat Kepercayaan | Nilai Z * - |
|---|---|
| 80% | 1.28 |
| 90% | 1.645 (konvensional) |
| 95% | 1.96 |
| 98% | 2.33 |
| 99% | 2.58 |
Tabel di atas menunjukkan nilai z * untuk tingkat kepercayaan yang disediakan. Perhatikan bahwa nilai-nilai ini diperoleh dari distribusi normal standar (Z-).
Area antara setiap nilai z * dan negatif dari nilai ini adalah persentase kepercayaan (perkiraan). Misalnya, area antara z * = 1.28 dan z = -1.28 adalah sekitar 0, 80. Oleh karena itu, tabel ini juga dapat diperluas ke persentase kepercayaan lainnya. Tabel tersebut hanya menunjukkan persentase kepercayaan yang paling umum digunakan.
Lihat juga arti Hipotesis.


